Конспект
Современное человечество переживает пятую технологическую революцию, связанную с повсеместным внедрением технологий искусственного интеллекта. Ее влияние на жизнь людей уже сейчас огромно и будет только усиливаться, подобно тому, как в свое время электричество или интернет стали неотъемлемой частью быта. В основе этой революции лежит машинное обучение — раздел компьютерных наук, занимающийся автоматическим поиском закономерностей в данных. Его стремительный взлет стал возможен благодаря симбиозу современных математических методов и новых вычислительных технологий, в первую очередь графических ускорителей. Именно возможность выполнять параллельно огромное количество операций линейной алгебры, необходимых для обучения нейросетей, дала толчок к их взрывному развитию. Обучение модели, которое на обычном процессоре заняло бы годы, на графическом ускорителе стало занимать сутки, что и открыло дорогу для практического применения сложных нейросетевых архитектур.
Исторический контекст
Чтобы понять место искусственного интеллекта, полезно оглянуться на предыдущие технологические уклады. Каждая революция — это комплекс технологий, радикально меняющий жизнь подавляющего большинства людей.

Первой такой революцией стала эффективная паровая машина. Ее появление привело к созданию железных дорог и пароходов, которые на порядок снизили стоимость логистики. Если до их появления стоимость доставки занимала до семидесяти процентов в цене товара, то после — лишь около полутора процентов, что вызвало колоссальный экономический бум. Одновременно началась массовая автоматизация производства и процессы урбанизации.
Следующая революция на рубеже XIX-XX веков была связана с электричеством и двигателем внутреннего сгорания. Двигатель внутреннего сгорания, будучи на порядок эффективнее и компактнее паровой машины, подарил миру автомобиль и авиацию. Однако настоящим прорывом стало распространение электричества, которое позволило разнести генерацию энергии и ее потребление. Это кажется очевидным сейчас, но до этого человечество экспериментировало с диковинными альтернативами, вроде сети пневматических труб для подачи сжатого воздуха в дома Парижа, где даже лифты десятилетиями работали на пневматике.
Интернет совершил революцию в коммуникациях и доступе к информации, сделав персональный компьютер по-настоящему мощным инструментом. Без сети компьютер использует лишь малую часть своего потенциального функционала.
Искусственный интеллект является пятой технологической революцией. Его суть заключается в передаче компьютеру задач, требующих не просто вычислений, а выявления скрытых, неочевидных для человека зависимостей. Это меняет парадигму с создания алгоритмов человеком на обучение алгоритмов на данных.
Основы машинного обучения: черный ящик и его ручки
Суть машинного обучения можно свести к поиску скрытых закономерностей в данных. Данные — это совокупность объектов, каждый из которых описывается наблюдаемыми переменными и целевыми переменными. Задача — построить алгоритм, который по наблюдаемым переменным предсказывает целевые.
Такой алгоритм можно представить как «черный ящик» с множеством регулируемых «ручек». Процесс обучения — это настройка этих ручек таким образом, чтобы на известных объектах, обучающей выборке, прогнозы черного ящика максимально совпадали с правильными ответами. В современных больших моделях количество таких «ручек» может достигать сотен миллиардов, и их настройка возможна только с помощью сложных методов математической оптимизации.
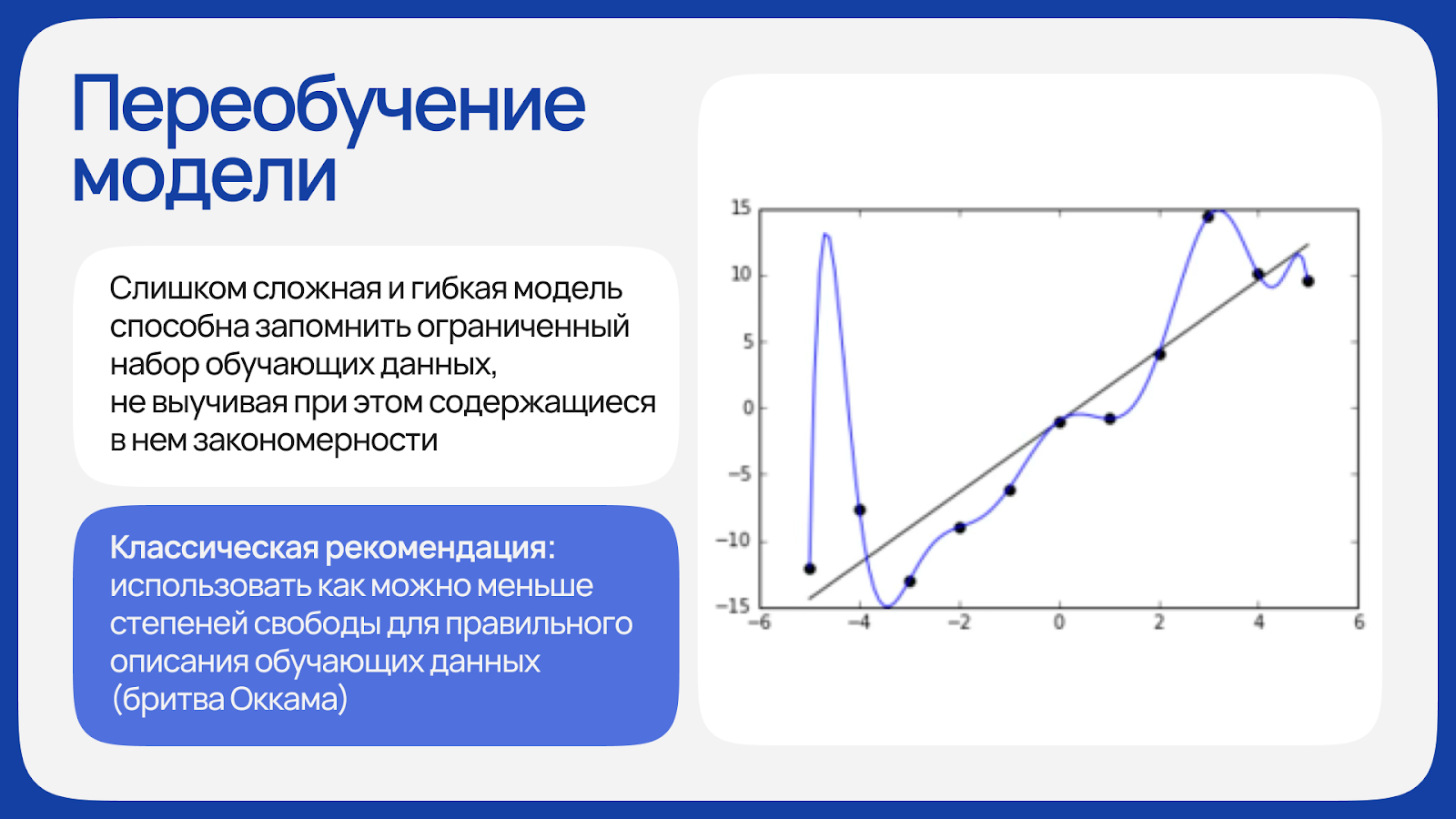
Классической проблемой машинного обучения является переобучение. Это ситуация, когда модель вместо выявления общих закономерностей просто заучивает примеры из обучающей выборки, демонстрируя на них идеальную точность, но плохо работая на новых данных. Исторически считалось, что с ростом сложности модели ошибка на новых данных сначала падает, а потом, после точки переобучения, снова начинает расти. Однако в нейросетях был обнаружен парадоксальный эффект «двойного спуска» — после точки переобучения ошибка снова начинает снижаться. Объясняется это тем, что более сложные модели, вопреки интуиции, находят более простые и общие правила.

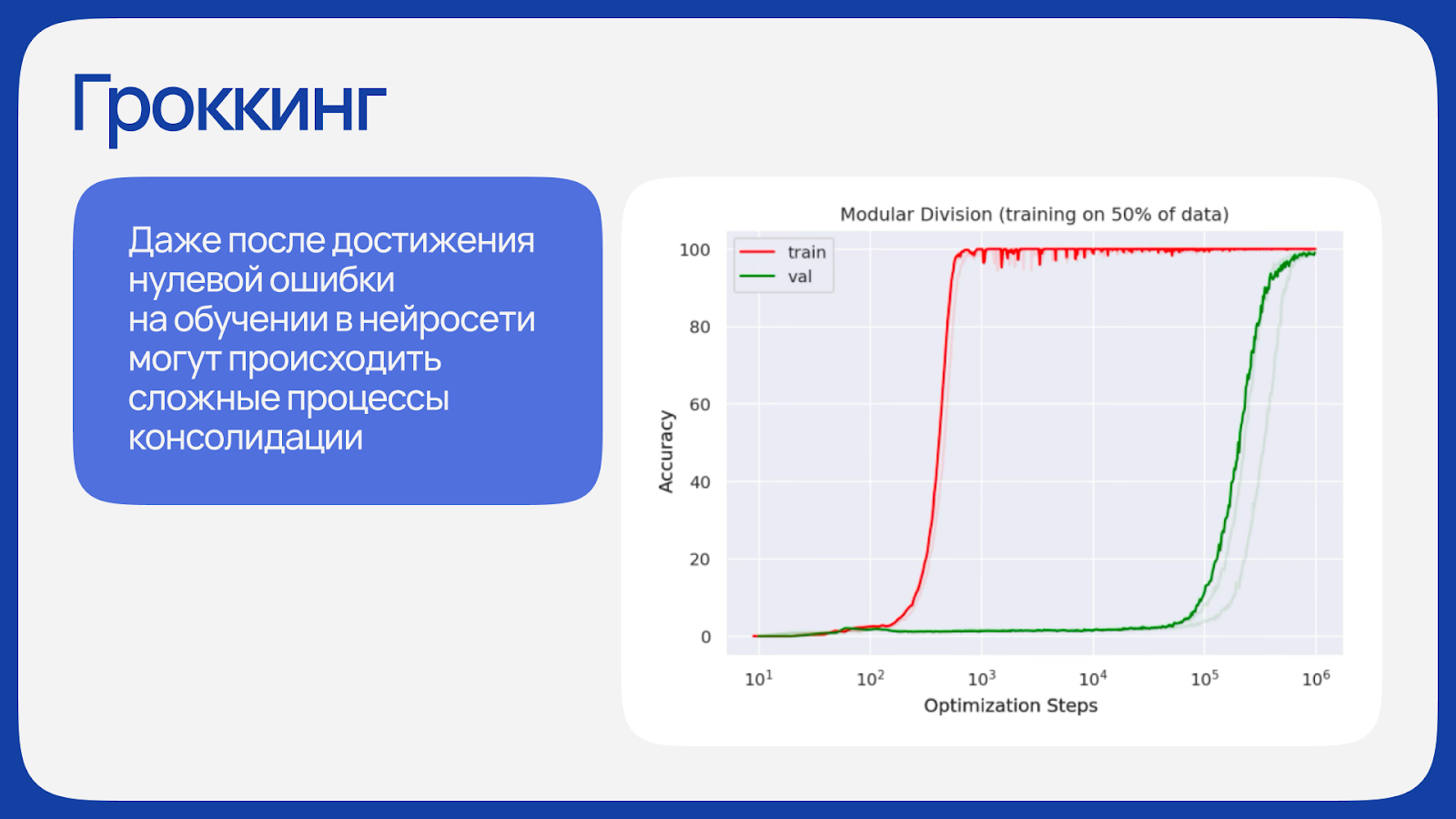
С развитием больших моделей проявились и другие загадочные феномены. Один из них — гроккинг. Модель сначала быстро достигает ста процентов точности на обучающей выборке, что выглядит как катастрофическое переобучение. Но если обучение продолжить, через значительное время, иногда в сотни раз дольше, точность на тестовой выборке внезапно резко возрастает. Модель словно «переосмысливает» выученное, переходя от механического запоминания к пониманию общего правила. Этот эффект мог быть открыт случайно, когда исследователи оставили обучение работать на выходных после того, как модель уже достигла совершенной точности на обучающей выборке.
Другой эффект — связанные минимумы. Оказывается, в пространстве параметров нейросети существуют целые «долины» — пути, соединяющие разные комбинации параметров, которые дают нулевую ошибку на обучении. Модель, используя стохастические алгоритмы оптимизации, может «дрейфовать» по этим долинам из «плохого» минимума, соответствующего запоминанию, в «хороший» минимум, соответствующий обобщению. При этом обратный дрейф из хорошего минимума в плохой не наблюдается. Эти открытия показывают, что современные протоколы обучения далеки от оптимальности, и внутренние процессы в больших нейросетях до конца не изучены.
Диффузионные и большие языковые модели

Современный бум в искусственном интеллекте связан с двумя типами генеративных моделей, которые создают сложные объекты, а не просто классифицируют их.
Диффузионные модели — это физически вдохновленный подход, основанный на аналогии с термодинамикой. Прямой процесс — это постепенное «зашумливание» картинки, пока она не превратится в чистый случайный шум, что соответствует росту энтропии. Обратный процесс — это постепенное «очищение» шума для генерации новой картинки, что означает уменьшение энтропии.

Для реализации обратного процесса, невозможного в замкнутой системе, нейросеть учится рассчитывать специальный поправочный член, играющий роль «внешнего источника информации». Эта элегантная математическая концепция легла в основу современных систем генерации изображений по текстовому описанию. Эти модели применяются не только к картинкам, но и к другим данным, например, для синтеза молекул и кристаллических решеток с заданными свойствами. При этом попытки применить диффузионные модели для генерации текста пока не увенчались успехом.
Большие языковые модели, такие как GPT, построены на архитектуре трансформеров, использующей механизм внимания. Этот механизм позволяет модели динамически решать, каким частям входного текста уделять больше «внимания» при генерации ответа.

Ключевое их преимущество — способность обучаться на колоссальных объемах текстовых данных. Текст является универсальным носителем информации, в который можно перевести знания практически из любой области. Модели обучаются на задачах предсказания следующего слова или восстановления пропущенных фрагментов текста. В ходе этого обучения они неявно постигают синтаксис, семантику и логику, что позволяет им в дальнейшем генерировать осмысленные тексты, отвечать на вопросы и поддерживать диалог, иногда демонстрируя зачатки юмора и самоиронии. По сути, они становятся агрегаторами коллективного знания человечества, содержащегося в интернете. Обучение часто проходит в два этапа: сначала модель учится восстанавливать пропущенные слова в огромном корпусе текстов, этап предварительного обучения, на котором она постигает «смысл», а затем дообучается на меньших наборах данных «вопрос-ответ» для выполнения конкретных задач. Именно такая комбинация технологий, без единой принципиально новой идеи, но грамотно собранная воедино, привела к появлению ChatGPT. Первая реакция многих специалистов заключалась в недоверии, казалось невероятным, что такая модель не является фейком, за которым стоят живые люди.
Возможности и риски

Внедрение искусственного интеллекта уже сейчас автоматизирует множество рутинных задач, от написания кода и научных статей до составления юридических документов. Это ведет к революции в информационном поиске и создает риск массового сокращения спента на интеллектуальный труд. Современные большие модели могут использоваться для получения справок и решения бытовых вопросов, где традиционный поиск уже не справляется.
Однако у искусственного интеллекта есть фундаментальные ограничения. У него отсутствует эмпатия, сознание, целеполагание и понимание последствий своих действий в человеческом смысле. Это порождает серьезные этические и юридические вызовы. Кто несет ответственность за действия искусственного интеллекта, если он даст фатально неверный совет, как в случае с подростком, которому чат-бот подсказал способ суицида? Кому принадлежат права на созданный им контент? Стоит ли доверять ему принятие решений в критических областях, таких как управление оружием или критической инфраструктурой? Способность искусственного интеллекта генерировать убедительный текст открывает дорогу для беспрецедентных по масштабу манипуляций общественным мнением. Современные коммерческие модели уже содержат секретные системные промпты, которые невидимо для пользователя добавляются к каждому запросу, запрещая модели обсуждать определенные темы, что является прообразом встроенных протоколов безопасности.

Что касается профессий будущего, то, парадоксальным образом, наиболее защищенными могут оказаться специальности, связанные с ручным трудом и мелкой моторикой — сантехники, сортировщики мусора, сиделки, так как робототехника пока безнадежно отстает в решении этих задач. Робот-рука, способная открыть дверную ручку, считается большим достижением, а завязать шнурки — пока недостижимой целью. Среди новых профессий будущего выделяются ассесоры-разметчики данных, специалисты по уходу за пожилыми людьми и контролеры искусственного интеллекта, которые будут надзирать за его решениями в критических системах.
Пессимистический сценарий будущего — это мир киберпанка с растущим неравенством, массовой безработицей и деградацией образования. Оптимистический — экономический бум за счет роста производительности, введение безусловного базового дохода и гармоничное сотрудничество человека и машины. Для реализации позитивного сценария необходимы протоколы безопасности, встраивание этических директив в модели, взаимный контроль систем искусственного интеллекта и, возможно, создание международных исследовательских центров по аналогии с ЦЕРНом для контроля над разработкой самых мощных систем искусственного интеллекта. Даже в фантастических вселенных, борющихся за свободу, искусственный интеллект не допускается до принятия стратегических решений на военных советах, что отражает текущие антропоцентрические установки общества.

